Chatbot de support: Créez votre premier assistant IA sur vos documentations
Découvrez comment construire un chatbot fiable, nourrit de votre propre documentation. Apprenez comment exploiter la puissance de Python, Langchain et l'API OpenAI pour créer un chatbot qui exploite vos données.
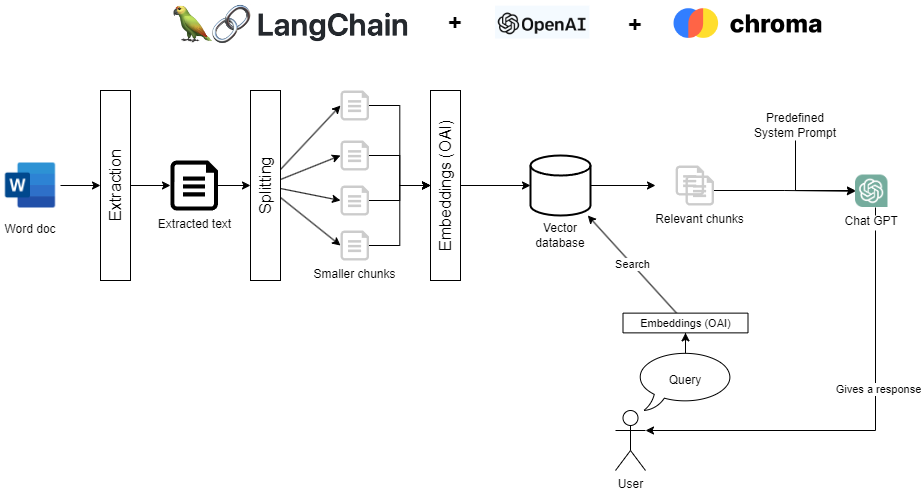
Introduction
Dans ce billet de blog, je vous guiderai à travers le processus de création de votre propre chatbot de support alimenté par l'IA qui utilise votre documentation existante pour fournir une assistance précise. Ce guide est ma façon de participer au mouvement ChatGPT actuel, en expliquant avec mes propres mots comment s'initier au sujet et comprendre les bases. En exploitant Python, Langchain et l'API OpenAI, je vais vous montrer comment transformer votre documentation en sources précieuses pour votre chatbot. Nous couvrirons les étapes de la décomposition de vos documents en fragments, de leur conversion en vecteurs et de leur stockage dans ChromaDB. Cette approche permet à votre chatbot d'accéder aux informations dont il a besoin pour offrir des réponses contextuelles efficaces. De plus, nous discuterons des meilleures pratiques pour élaborer un prompt ChatGPT consciente du contexte, en veillant à ce que votre chatbot offre des réponses fiables et utiles en évitant les "hallucinations" (inventer des informations fausses). Rejoignez-moi dans cette aventure pour créer un chatbot de support qui non seulement satisferont vos utilisateurs, mais améliorera également votre expérience de support client.
Configuration de l'environnement de développement
Avant de plonger dans le monde passionnant du développement de chatbots, il est crucial de configurer correctement votre environnement de développement. Avoir les bons outils et configurations vous assure un développement fluide et sans accroc, vous permettant de vous concentrer sur la création de votre chatbot de support alimenté par l'IA.
Nous allons parcourir les outils, bibliothèques et API essentiels dont vous aurez besoin pour commencer. Nous couvrirons également le processus d'installation et vous guiderons à travers la configuration des clés API.
Outils, librairies et API nécessaires
Pour créer votre chatbot, vous aurez besoin des éléments suivants :
- Python : un langage de programmation polyvalent largement utilisé dans le monde de l'IAet plus largement de la data science. Téléchargez la dernière version de Python depuis le site officiel : https://www.python.org/downloads/
- Langchain : un outil puissant pour travailler avec des données textuelles, en particulier lorsqu'il s'agit de diviser et de gérer des fragments de documents. Il est également devenu un élément essentiel de le chainage d'actions vers l'API Open AI comme ChatGPT.
- OpenAI API : l'API OpenAI fournit un accès à des modèles de langage puissants tels que GPT-3 / GPT-4 et plus récemment ChatGPT, que nous utiliserons pour la création des embeddings de documents et la génération de réponses de chatbot. Pour commencer avec l'API OpenAI, rendez-vous sur le site web OpenAI et inscrivez-vous pour obtenir un compte et obtenir votre clé API : https://platform.openai.com/. Notez que vous serez facturé pour l'utilisation de cette API, alors assurez-vous de ne pas utiliser une quantité trop importante de données pour vos premiers tests et surveillez attentivement votre consommation d'API.
Processus d'installation
Une fois que vous avez téléchargé Python, suivez ces étapes pour installer Langchain, Chroma et configurer l'API OpenAI :
- Installer les dépendances de pip : ouvrez un terminal ou une invite de commande et exécutez la commande suivante :
# Langchain, l'orchestrateur pour notre chatbot
pip install langchain
# La base de données vectorielle Chroma
pip install chromadb
# Librairie pour extraire du texte d'un document Word
pip install unstructuredCela installera Langchain et ses dépendances ainsi que Chroma, une base de données vectorielle ainsi qu'une petite dépendance pour extraire des informations d'un document Word.
- Configurer l'API OpenAI : après vous être inscrit à un compte OpenAI, vous devez créer une clé API depuis votre compte sur le site web plateform.openai.com. Pour Linux et macOS, exécutez la commande suivante dans votre terminal :
export OPENAI_API_KEY="votre_clé_api_ici"Pour Windows, ouvrez une invite de commande et exécutez :
set OPENAI_API_KEY="votre_clé_api_ici"N'oubliez pas de remplacer "votre_clé_api_ici" par la clé API réelle que vous avez obtenue sur la plateforme OpenAI.
Maintenant que vous avez configuré votre environnement de développement, vous êtes prêt à commencer à construire votre chatbot. Dans le prochain chapitre, nous plongerons dans le processus d'ingestion de votre documentation et de sa conversion en embeddings à l'aide de Python, Langchain et l'API OpenAI.
Ingestion et traitement de votre propre documentation
Maintenant que votre environnement de développement est prêt, il est temps de plonger dans le cœur de notre chatbot de support : l'ingestion et le traitement de votre documentation. Je vous guiderai à travers le découpage de vos documents en fragments plus simple à manipuler, leur transformation en embeddings à l'aide de l'API OpenAI et leur stockage dans ChromaDB pour une récupération efficace.
Chargement d'une documentation et décomposition en fragments
Tout d'abord, nous devons décomposer votre documentation en plusieurs fragments. Ce processus nous permettra d'envoyer au chatbot uniquement les fragments pertinents en tant que contexte afin qu'il puisse répondre à la question de l'utilisateur.
Voici comment vous pouvez charger un document Word en utilisant Langchain, n'oubliez pas que vous aurez besoin de la bibliothèque "unstructured".
À la fin de cette méthode, loaded_document contiendra un tableau d'un objet Document unique contenant l'ensemble du contenu de votre fichier Word. Notez que les données ne sont pas encore divisées à ce stade et que vous ne pouvez pas alimenter l'ensemble du document à ChatGPT en tant que contexte (principalement en raison des limites du nombre de tokens d'entrée).
from langchain.document_loaders.word_document import UnstructuredWordDocumentLoader loader = UnstructuredWordDocumentLoader("user_doc_fr.docx") loaded_document = loader.load()La prochaine étape consiste donc à diviser ce grand document en plusieurs parties plus petites, en utilisant à nouveau les capacités intégrées de Langchain.
Cela va diviser le document en plus petits fragments d'au maximum 1000 caractères. Sachez que la division est effectuée de manière intelligente pour conserver les phrases dans le même fragment et éviter de les couper en plein milieu. Vous pouvez obtenir plus de détails en lisant la documentation complète de RecursiveCharacterTextSplitter en cliquant ici.
Dans mon exemple, j'avais 32 fragments pour un document original d'environ 50 pages Word.
Créer des embeddings et les stocker localement
Ensuite, nous allons convertir ces fragments de texte en embeddings à l'aide de l'API OpenAI. Ces embeddings sont des représentations numériques compactes de la sémantique du texte qui permettent une récupération facile et extrêmement rapide en fonction du sens sémantique des fragments.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
# Cette ligne fait beaucoup de choses en sous-marin, elle convertit les
# fragments en embeddings, appelle l'API OpenAI (attention aux coûts d'API !),
# puis les stocke localement dans notre base de données
Chroma.doc_search = Chroma.from_documents(splitted, embeddings)Comme vous pouvez le voir, Langchain aide beaucoup ici à faciliter l'ensemble du processus, mais vous devez comprendre qu'en arrière-plan, toutes ces actions sont effectuées :
- Chaque fragment est envoyé au moteur d'embedding OpenAI pour le transformer chaque fragment en un vecteur de nombres flottants, représentant leur signification sémantique.
- Chaque vecteur généré de cette manière est stocké dans Chroma pour une récupération ultérieure.
Veuillez noter que par défaut, le stockage de Chroma se fait en mémoire et ne sera pas persisté.
Gestion des requêtes utilisateur et génération de réponses contextuelles avec ChatGPT
Avec votre documentation traitée et stockée dans ChromaDB, il est temps de donner vie à votre chatbot de support. Nous allons voir comment gérer les requêtes utilisateur, les associer à des fragments de documents pertinents et générer des réponses contextuelles à l'aide de ChatGPT.
Conversion des requêtes utilisateur en embeddings et récupération des fragments pertinents
Lorsqu'un utilisateur soumet une requête, nous devons d'abord la convertir en un embedding pour trouver les fragments les plus pertinents dans ChromaDB. Voici comment faire très facilement avec langchain :
retriever = doc_search.as_retriever()
query = """Comment supprimer mon compte ?"""
# Cette ligne fait encore beaucoup de choses comme interroger l'API OpenAI
# pour transformer la requête en embedding puis la comparer à tous les embeddings
# stockés dans la base de données Chroma locale pour trouver la pièce de documentation la plus pertinente.
relevant_docs = retriever.get_relevant_documents(query)À la fin de ce code, vous aurez 4 (nombre par défaut) fragments extraits de ChromaDB qui sont sémantiquement les plus proches de la requête utilisateur. Ce sont les 4 fragments que nous fournirons à ChatGPT pour être en mesure de répondre à la question de l'utilisateur avec le bon contexte.
Génération de réponses contextuelles avec ChatGPT
Avec les fragments pertinents identifiés, nous allons maintenant les utiliser comme contexte pour générer une réponse de ChatGPT. La partie clé de cette étape est de fournir une bonne instruction système qui permettra à ChatGPT de se comporter comme vous le souhaitez.
Je mets ici un exemple, mais il existe de nombreuses ressources sur Internet pour l'améliorer et l'adapter à vos besoins.
from langchain.chat_models import ChatOpenAI
from langchain.schema import (SystemMessage, HumanMessage)
# La température à 0 ici empêchera le chatbot de s'emballer sur les réponses
# et rester plus pragmatique.
chat = ChatOpenAI(temperature=0)
# Concaténez tous les fragments pertinents identifiés précédemment
only_contents = map(lambda d : d.page_content, relevant_docs)
concatenated_found_docs = '\n'.join(only_contents)
# L'instruction système est la chose la plus importante pour diriger votre chatbot
# En plus du contexte, vous devez spécifier le comportement que vous voulez qu'il adopte
# Face au contexte, instruisez l'IA pour qu'elle
systemMessage = SystemMessage(content= """
Tu es un assistant très intelligent qui ne répond qu'aux questions sur les sujets de <Nom de votre produit> et <Votre domaine d'application>.
Vous êtes très poli et enjoué.
Je vais te donner plusieurs parties de documents que tu utiliseras comme contexte pour élaborer ta réponse.
Tu n'inventeras rien sous aucun pretexte et tu ne répondras pas si le contexte que je t'ai donné ne contient pas l'information.
Si cela ce produit, tu répondras simplement dans la langue appropriée "Je suis désolé, je n'ai pas la connaissance appropriée, vous pouvez contacter l'équipe de support sur support@myapp.com pour obtenir une réponse complète à votre question"
Maintenant, voici les phrases qui te servent de contexte : """ + concatenated_found_docs)
humanMessage = HumanMessage(content=query)
chat_result = chat([systemMessage, humanMessage])
Chat GPT 3.5 sera utilisé comme modèle par défaut, mais si vous y avez accès, vous pouvez spécifier le modèle ‘gpt-4’ dans le constructeur de ChatOpenAI, essentiellement parce qu'il est bien meilleur pour être orienté par le System Prompt.
Votre chatbot fournira maintenant une réponse qui prend en compte les informations pertinentes de votre documentation et qui reste en ligne avec vos directives.
Conclusion
Félicitations pour avoir réussi à créer votre propre chatbot de support en utilisant Python, Langchain, OpenAI API et ChromaDB ! En suivant ce guide, vous avez créé un chatbot capable de fournir des réponses contextuelles basées sur votre documentation existante. Ce chatbot a le potentiel d'améliorer votre expérience de support client, de rationaliser vos opérations et de satisfaire les utilisateurs.
Cependant, il est important de noter que le chatbot que nous avons construit dans ce tutoriel sert de Proof of Concept (PoC). Lors de la transition vers un environnement de production, plusieurs facteurs doivent être pris en compte et des améliorations doivent être apportées.
Une considération clé est le choix de la base de données vectorielle. Bien que nous ayons utilisé ChromaDB pour notre exemple, il existe de nombreuses bases de données vectorielles disponibles avec des fonctionnalités, des performances et une évolutivité variables. Une évaluation et une sélection soigneuses de la bonne base de données pour votre cas d'utilisation spécifique est essentielle pour des performances et une efficacité optimales.
De plus, il est crucial de procéder à des tests approfondis pour s'assurer que les réponses du chatbot restent dans le cadre attendu et correspondent aux exigences de votre entreprise. Cela peut impliquer de raffiner le seuil de similarité du chatbot, d'améliorer la qualité des données d'entrée ou d'affiner les paramètres du modèle ou le System Prompt pour obtenir une meilleure précision de réponse.
En conclusion, le chatbot que nous avons conçu dans ce tutoriel démontre le potentiel des chatbots de support alimentés par l'IA en utilisant votre propre documentation. En prenant ce PoC comme point de départ et en abordant les considérations mentionnées ci-dessus, vous pouvez développer une solution prête pour la production qui révolutionne votre expérience de support client.
Bonne chance et bon code !
Pour découvrir mon logiciel de notes de frais ONexpense et une comparaison des alternatives